Cloud calibration
SWAT+ calibration and validation on AWS EC2
Each calibration job gets its own dedicated EC2 instance, sized to the model — the swarm runs in parallel, progress streams live to your dashboard, and the box terminates the moment results sync.
Preview — offered to Pro users by request while self-serve access rolls out.
- Per-job dedicated compute
- Parallel role-aware MMPSO
- Live convergence on your dashboard
- Auto-terminate — no idle compute
- AWS compute billed at cost
Calibrating a large SWAT+ model is compute-bound: a particle swarm runs the model thousands of times to fit observed streamflow. On a laptop that can take days to weeks. SWATGenX instead dispatches the swarm to a dedicated AWS EC2 instance and runs the forward runs in parallel. That parallelism works at two levels: the swarm evaluates many forward runs at once, and each forward run can itself go multi-core on the SWATGenX parallel SWAT+ engine (an opt-in per-job setting — see the parallel engine page).
Everything below is fact-based: the wall-time examples come from a measured six-model runtime sweep on the production SWAT+ engine, and the instance and spot/on-demand choices are made automatically from each model’s size and estimated run length.
Key takeaways
- Each job runs on its own dedicated EC2 machine, not a shared queue — the instance size is chosen automatically so the parallel swarm fits in cores and RAM.
- Spot vs on-demand is chosen automatically from estimated run length, and a reclaimed spot box auto-resumes on on-demand from the last checkpoint — an interruption costs a little time, never the run.
- You can watch the swarm converge live on your dashboard and stop the run whenever you judge the fit good enough — you keep the best parameters found so far, and the instance terminates the moment results sync.
How it works
How a calibration job reaches AWS
- 1Bundle
Your built model plus the pinned SWAT+ engine binary are packaged into a ~32 MB bundle on the SWATGenX server.
- 2Select
The instance size is picked from the model (cores plus the RAM needed to hold the parallel swarm), and the pricing model from the estimated run length — interruptible spot for short jobs, dedicated on-demand for jobs of roughly an hour or more so they can't be reclaimed mid-run.
- 3Run & monitor
The PSO swarm runs on the box — forward runs are evaluated in parallel across the cores, and each forward run can itself go multi-core with the opt-in parallel SWAT+ engine. Live progress streams back to your dashboard every ~20 seconds: objective metrics, the initial-stage hydrograph, and the global-best and per-particle convergence curves. You can watch the swarm converge and stop the run whenever you judge the fit is good enough — you keep the best result so far. If AWS reclaims a spot box mid-run, the job restarts automatically on an on-demand instance from the last checkpoint.
- 4Fetch & terminate
Calibrated parameters, metrics and hydrographs sync to your dashboard, then the instance terminates automatically (a shell trap guarantees it, even on error).
The optimizer default is role-aware MMPSO — mentor, mentee, and independent particles sharing multiple memories — with single-swarm PSO as the fallback. See calibration methods for the full method.
Server options
Instance options (c7i, us-east-1)
| Instance | vCPU | RAM | Role |
|---|---|---|---|
| c7i.8xlarge | 32 | 64 GiB | Default — fits almost every basin |
| c7i.16xlarge | 64 | 128 GiB | Large swarms / faster big-basin turnaround |
| c7i.48xlarge | 192 | 384 GiB | Maximum parallelism |
The instance is chosen automatically so the parallel swarm fits in memory and finishes fastest. RAM is the binding limit: each forward run needs roughly 0.5–4 GiB, so a 64 GiB box runs about 16 in parallel and a 128 GiB box about 32. Bigger swarms or big basins benefit from the larger instances — but the large sizes are subject to AWS capacity and account quotas, and may launch on-demand rather than spot.
How long it takes
Compute time by basin size (measured models)
Reference workload: 7-year calibration window, 32-particle swarm x 50 PSO iterations + 32 warm-up samples (1,632 forward runs).
| Basin | Model | HRUs | Channels | Per run | Wall time | Runs on |
|---|---|---|---|---|---|---|
| Small | 03080102b | 1,202 | 100 | 0.33 min | 17 min | Spot |
| Medium | 09471300 | 11,284 | 1,371 | 2.89 min | 2.5 h | On-demand |
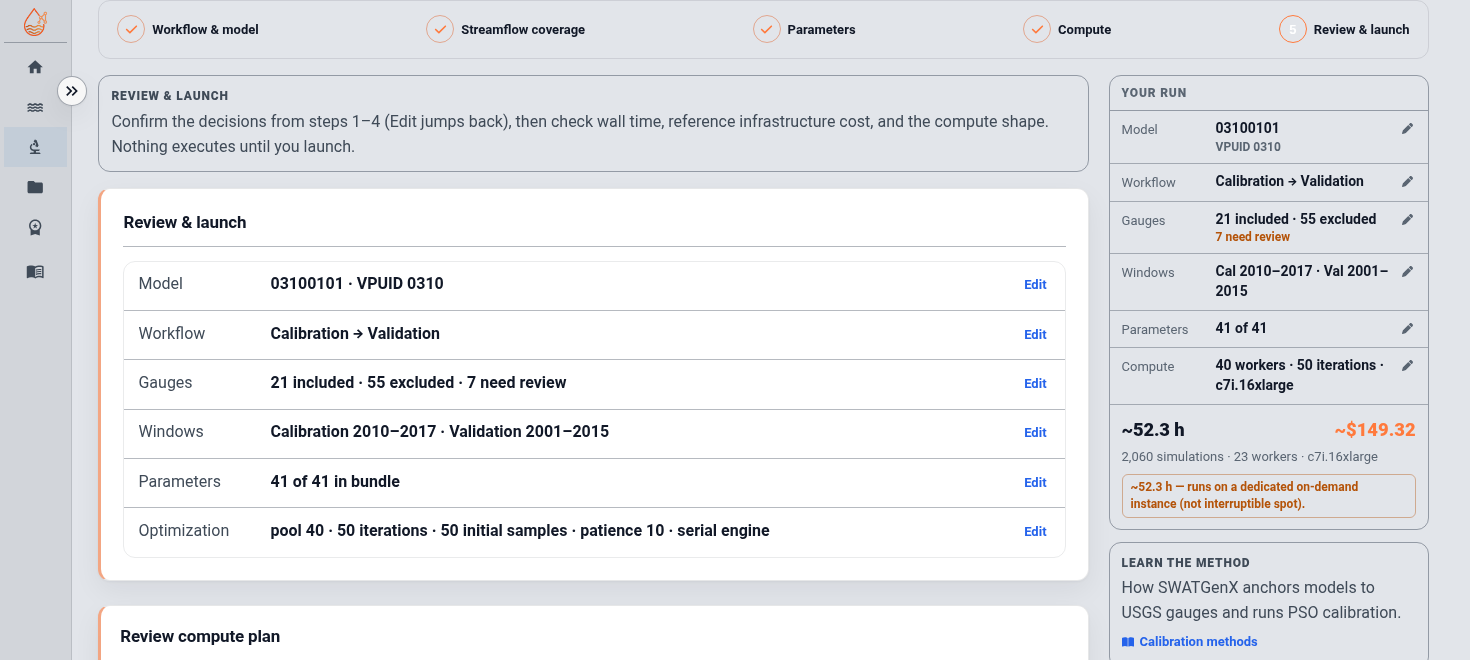
| Large | 03100101 | 94,303 | 8,181 | 30.80 min | 26.7 h | On-demand |
Each row is a real SWATGenX model from the runtime sweep (engine 247e95b, NetCDF + print-filter), for a 7-year window and a 32-particle x 50-iteration PSO (1,632 forward runs) on one c7i.8xlarge. "Runs on" is the pricing model SWATGenX selects from the estimated wall time. Big basins finish faster on a larger instance or with a smaller swarm; swarm-level parallelism here is capped at the 32-particle pool, and the opt-in parallel SWAT+ engine can additionally put multiple cores on each forward run.
What a real calibration costs
One measured example, not a quote — cost scales with basin size, window, and swarm settings; the wizard estimates your run before launch.
The fine print
Availability and accuracy
- Cloud calibration is in preview and offered to Pro users by request — it is not yet a self-serve checkout.
- Spot capacity is not guaranteed: a short job may wait briefly for a slot, and AWS can reclaim a spot box mid-run. SWATGenX surfaces the wait on your dashboard and, on a reclaim, automatically resumes the job on a non-reclaimable on-demand instance (warm-started from the latest checkpoint) — so spot interruptions never lose work. Long jobs run on on-demand capacity from the start.
- Runtime constants were fit (R²=0.996) to a six-model sweep and translated to c7i; your exact wall time depends on basin size, channel count, the calibration window, and swarm settings.
Engine 61.0.2.61-353-g247e95b · reference instances us-east-1.
FAQ
What AWS instance does SWATGenX use for calibration?
A spot c7i.8xlarge (32 vCPU / 64 GiB, Sapphire Rapids) by default. Larger swarms or big basins can use c7i.16xlarge (64 vCPU) or c7i.48xlarge (192 vCPU). Each calibration job gets its own dedicated instance — not a shared queue.
Does SWATGenX use spot or on-demand instances?
Both — chosen automatically from the estimated run length. Jobs that finish in under about an hour run on low-cost interruptible spot. Longer jobs run on a dedicated on-demand instance that AWS cannot reclaim mid-run, so a multi-hour calibration completes through validation instead of being interrupted partway. If a short spot job is reclaimed mid-run, SWATGenX automatically relaunches it on a non-reclaimable on-demand instance, warm-started from the last saved iteration, so the run still finishes. Either way the instance auto-terminates the moment results are fetched, so there is no idle compute.
How long does a calibration take on AWS?
Roughly 15-20 minutes for a small basin, a few hours for a mid-size model, and up to ~1 day for the largest continental basins on a single 32-core instance. Wall time scales with HRU and channel count, the calibration window, and the swarm size; bigger swarms or instances finish large basins faster.
Can I watch the calibration live and stop it myself?
Yes. Progress streams to your dashboard every ~20 seconds — objective metrics, the initial-stage hydrograph, and the global-best and per-particle convergence curves — so you can see how the swarm is converging in real time. You can stop the run at any point based on your own judgment of the fit (for example, once the global best has plateaued); SWATGenX keeps the best parameters found so far and shuts the instance down.
Do I have to manage any AWS infrastructure?
No. SWATGenX bundles your model with the pinned SWAT+ engine, launches the instance, runs the PSO swarm, streams live progress to your dashboard, fetches the results, and terminates the machine automatically — you only see the calibrated parameters, metrics and hydrographs.
Is cloud calibration available now?
It is in preview and offered to Pro users by request. The infrastructure is live and validated; contact us to enable it for your account while we roll out self-serve access.
Related guides
Explore related
Last updated 2026-06-11.